|
�������̣���ԪUniVLA�û�����"��ѧ�ɲ�"
2025-08-07 15:48:56
��Դ:
���:2 0��
���峿�������ս����䣬����Ż�����˵��"��һ�����"��ָ����������ز������Ȼ����嵰��——���ƻó���������Ԫ�����˵�UniVLAϵͳ�����ս���ʵ�����ڿ�Դ�����ͨ�ò��Կ�ܣ�ͨ���������Ϊ��Ƶ�ĵײ����壬ʹ�����״λ��"�۲�ѧϰ"��������Ԫ�����Ŷ�����ʵ֤��������ǧ�����˹���ע��������ͬ�������ո�������ܡ�
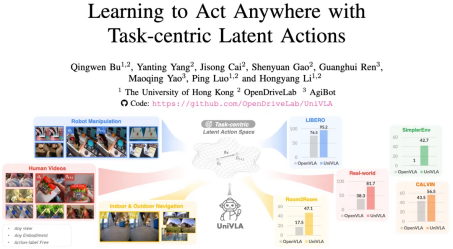
��ͳ������ѧϰ�������ݡ��������������ؼ���������������������ɼ���OpenVLA��2��+��ʾ������ѵ�����ij����������¿������֡�������е��ʱ���ؽ�ȫ�������ռ䡣����Ԫ�����˵��ƾ�֮�����ڴ���"����������Ŧ"��ͨ��ϵͳ�Զ��ֽ����������ƵΪ"Ŀ��-Լ��-����"��Ԫ�顣�ڹ�̨�ư����У����ܳ����"��λ��Դ-����������Ʒ-��ȷ��ѹ"�ĺ����������Ǽ������ؽڽǶȡ�����������ָ��"��èιʳ"ʱ��Ҳ�ᱻӳ�䵽��ʽ�����ռ��ι��ԭ�ͣ��������ޡ��������㵹��ԭ�Ӳ�����ϡ�������ʾ���÷����ڿ������гɹ�������18.5%����12M�ͽ�������ͬ��������٣������ռ�ָ��ת��Ϊ��ͬ�����˵Ŀ����롣
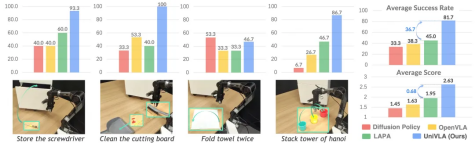
��Ϊ��Ҫ���ǣ���Ԫ����ͨ���������������Ƶ�������������ܽ����"�峴����"�Ķ�����ʽ��ѧϰ�ҾӲ���������Ƶ���ܴ�������ϳ�"��߷�������"���¼��ܡ����ֿ��Ż���ѧϰ�����������������ݱ��ݣ���ʹ����AgiBot World Challenge @ IROS 2025�г�Ϊ��ģ�͡�
��ʵ���ҵ���Դ�������ӹ�ҵ��������ͥ����UniVLA�������ܻ������ܵ�ϰ�÷�ʽ����Ԫ����������ʽ�����ռ����Կ�ף���˿籾�巺�������⡣����������������һ��ͨ���۲���Ƶ���ռ��ܣ������ڲ�Զ�Ľ�����ÿ����ͥ���ø��Ի������ܼҽ���Ϊ��Ԫ�����ջݵ����ע�š�
|
|
|