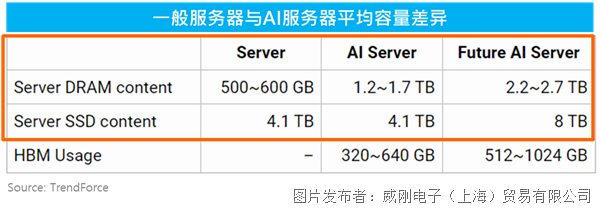
 |
|

|
|
���ձ����С���AI TIME ����̽��"���Ի��Ƽ�"
һ������ ����2012�����ͷ�������ߣ������ݡ����Ի��Ƽ���ö������ꡣ����ͷ��������“����ĵģ�����ͷ��”��һ�����ڻ�����ʱ�������ǹ����Ŀںţ���ʱ�ĸ��Ի��Ƽ���Ϊ��Ч��ȡ��Ϣ���ֶα������ǵĹ�ע��ϲ���� ����Щ�����Ŵ��ڶ�����˽�����ݰ�ȫ�Ĺ��IJ�����ߣ��Ը��Ի��Ƽ�������֮�����ϣ����Ի��Ƽ������ַ���˽����Ϣ�뷿��ϵ��һ�𡣽�����������Ҫ��ƽ̨�����������㷨�رռ��������û��ں�̨һ���ر�“���Ի��Ƽ�”�����ô�����ֽкá���ô���Ի��Ƽ�������һ���Ǵ��� �������Ի��Ƽ������л��� �������Ի��Ƽ��Ļ����Ǵ���“��”��“��Ϣ”֮��Ĺ�ϵ���������Ϣָ����“��Ʒ��Ϣ”���ڵ���ƽ̨����“��Ʒ��Ϣ”���ڶ���Ƶƽ̨����”��Ƶ��Ϣ“��������ָ����”��“����Ȥ�㣬���Ի��Ƽ�ϵͳ������ͨ���û�ע��ʱ��д�ĸ�����Ϣ���û�����ʷ�����Ϣ�ȶ�������ƶϡ� 01 “����”——��ǩ����������Ϣ ͨ�����û������䡢���õ���Ϣ�����ռ��������㷨���з������ռ������ݣ��û�����Ȥ��ϵ�����������ƣ��γɻ������ϳ�˵���û����������û�������������������չ����Ʒ�����Ի��Ƽ�ϵͳ����ܲ�����һ��Ϣ�������û�����϶���Ԫ���û���ǩ��ͬʱ��ϵͳ����Ʒ��ϢҲ������һ���������ھ������Ӷ��γ���Ʒ���� 02 �ٻ�——����ϲ����һ���� �ڹ������û��������Ʒ����֮���Ի��Ƽ�ϵͳ�����������ռ���������ȥ��ϵ“��”��”��Ʒ“�����Ի��Ƽ���Ҫ�ֳ��ٻغ����������֣��ٻص���Ҫ���þ��Ǿ����ܵ��ҵ��û����ܸ���Ȥ����Ʒ�����������㷨����Эͬ�����㷨�� �� Эͬ�����㷨 ����˼�壬Эͬ���˾���Эͬ��ҵķ��������ۺ����һ��Ժ�������Ϣ���й��ˣ�ɸѡ���û����ܸ���Ȥ����Ʒ�Ĺ��̡����ݼ���ʵ�ֲ�ͬ��Эͬ�����㷨�ֿɷ�Ϊ�����û����ƶȵ�UserCF��������Ʒ���ƶȵ�ItemCF�ͻ�������������ľ���ֽ�CF�� �� �����û����ƶȵ�Эͬ���� UserCF����Ҫ˼������Ȥ���Ƶ���ϲ�����Ƶ���Ʒ������˵�������Ƽ�������������Ϊ���Ƶ��û���ϲ������Ʒ�� �� ������Ʒ���ƶȵ�Эͬ���� ItemCF���Ǵ��û��й���Ϊ����Ʒ���֣��Ƽ���������ϲ������Ʒ���Ƶ���Ʒ����������쿴��һ��������С�¡�����ô���Ƽ������㷨��Ϊ���롶����С�¡��Ƚ����Ƶġ�����A�Ρ��ȶ����� �� ���ھ���ֽ��Эͬ���� ����ֽ�CF��˼���Ϊֱ�ӡ������û�����Ʒ�Ľ�����Ϊ��ʾΪһ���������о�����к��д����û�����Ʒ�������Ԫ�ش����û�����Ʒ�Ľ�����Ϊ�����������ֵȣ�������ֽ�CFϣ��������������Ƶطֽ�Ϊһ���û�������ʾ�����һ����Ʒ������ʾ����ij˻����Ӷ������������δ֪��Ԫ�ء� ��Эͬ�����㷨֮�������˺ܶ�����ӵ��ٻ��㷨������������ݵ��㷨�ȣ����䱾�ʻ��ǻ������ƶȵ��Ƽ���ͬʱ��Ϊ�˸�ȫ��ظ����û��Ķ�����Ȥ���Ƽ�ϵͳ��������ö�·�ٻصĻ��ƣ�ʹ�����ɵĺ�ѡ��Ʒ����ȫ������� 03 ����——�Ʋ��������Ȥ�� �������ٻ�֮���Ի��Ƽ�ϵͳ�Ѿ���ȡ������Ϊ�û����ܸ���Ȥ����Ʒ����һ���ٻؽλ�ȡ����Ʒ�������൱�࣬��ʱ����Ҫ�������ģ����ٻص���Ʒ���ж༶���������ϸѡ��������Ʒչʾ���û��� �� �����㷨��ԭ�� �����һ��������ֽ����ռ�����������ϢԤ���û�����Ʒ����ij����Ϊ��������ӹ����ղصȣ��Ŀ����ԡ�������̿�������ɽ��û���λ��ijһ����Ⱥ���ٸ������е���Ϣ������һ����Ⱥ���ڵ�ǰ��Ʒ��ƫ�ã���Ȼ���Ի��Ƽ�ϵͳ����Ⱥ�ķ�����ϸ�£��������������������������Ⱥ�ķ��飬�������ϻ���һ���¡� �� ���� �ھ�����������֮���Ի��Ƽ���ʱ�ᾭ��������һ���棬Ϊ�˱�֤�û���������Ϣ����һ���Ķ����ԣ�ƽ̨����������������д�ɢ��ʹ���û��������Ƽ�����������ͬ�ʻ������⣬���ƽ̨��Ӫ�Ļ�������ԣ����ܻ�����������е��������磬���衶����С�¡��͡�����A�Ρ��������Ԫ��Ⱥ����ضȽ��ƣ����������ڡ�����A�Ρ����ṩ�̳�Ǯ�Ƚ϶࣬Ҳ���ܻᵼ�¡�����A�Ρ��������ڡ�����С�¡�֮ǰ�� �� ��ο������Ի��Ƽ� �˽��˸��Ի��Ƽ���ԭ������ô���Ի��Ƽ��Ƿ����һ���Ǵ��أ��𰸱�Ȼ�Ƿġ�����������˵�����Ի��Ƽ����������Ϣ���صĽ������ȥ��Ч��ȡ�Լ�����Ȥ����Ϣ�����⡣������ʱ������������Ϣ�����ᵼ��������ʧ���У����������������ҪѰ�ҵ����ݡ�����һ�£�������ʧȥ���Ի��Ƽ���������Ҫÿ�쿿��һ����һ���ظ�������ɸѡ��������ȥ�ҵ��Լ��뿴�����ݣ����������˵�γ�����һ�ֱ������ĥ�أ� 01 ��ħ���ĸ��Ի��Ƽ� �Ը��Ի��Ƽ���������Ҫ�����㣬һ�����и��Ի��Ƽ��ᵼ����Ϣ�뷿�����Ǿ��ø��Ի��Ƽ��ַ����Լ�����˽�� �� ��Ϣ�뷿 ��Ϣ�뷿ָ���ǹ�ע����Ϣ�����ϰ���Եر��Լ�����Ȥ���������Ӷ����Լ����������������һ���“�뷿”�е�������˵��������ÿ��ֻ�����ͬ�ʻ������ݡ������ڸ��Ի��Ƽ�ϵͳ������˵Ҳ��ϣ���û�������Ϣ�뷿����ƽ̨�Ƕȳ����ھ���û��������Ȥ��Ҳ����ζ�Ÿ����ӯ���㣬����һ������Ԫ�û�����ֻ�������Ԫ��Ʒ��������Ի��Ƽ�ϵͳ�Ƽ��������˶�����Ʒ��ʹ�ø��û��Ը���Ʒ����Ȥ����ô֮��Ϳ��ܽ��˶���IJ�Ʒ�������û��������ڰ����û���չ��Ȥ��ͬʱ���Ӫ�ա������ڸ��Ի��Ƽ�ϵͳ�У�̽���û�����Ԫ����ȤҲ��һ����Ҫ���� �� ��˽��ȫ �����㷨�ַ���˽�����⣬�Ƽ��㷨�����������ַ�������˽����˽������������ƽ̨���û����ݽ��л�ȡ������ķ�ʽ������û��ڲ�ͬƽ̨�ϵ����ݱ����Ϻ�������˽й¶�ķ��ձ����Ӿ硣��ˣ����ƽ̨��������Ϊ�û��ṩ���õĸ��Ի��Ƽ�Ϊ��ڣ����û����ݵ���˽�Ͱ�ȫ�����ַ������⣬ѧ����Ҳ�ڻ������о������ƽ̨�����д洢�û���Ϊ���ݵ�����¶Ը��Ի��Ƽ��㷨�����Ż��� �� ���� ��Ȼ������������������������е�����֮�⣬���Ի��Ƽ�ϵͳ�������������ڲ�����Ҫ�Ľ��ĵط����������Ի��Ƽ�ϵͳ�����������ں������û����������п��ܴ��ڸ��ָ�����ƫ��Ӷ������������ĸ��Ի��Ƽ�ϵͳ���ײ�������ƽ���Ƽ������ ���磬���Ի��Ƽ�ϵͳ��������ѧ��Ů�Ը�ϲ��ʱ�����ţ��Ƽ���Ů��ʱ�����ž������ռ����������û���������ʹ�ø��Ի�ϵͳ���ƫִ������ֻ��Ů���û��Ƽ�ʱ�����ţ�����һЩ�Դ˸���Ȥ�������û�����ȡ������Ƽ������⣬���Ի��Ƽ�ϵͳ���������������İѿ��������ض���Զ����α����Ƽ������š�����ʹ�ɿ�������۵�����Ҳ�Ǹ��Ի��Ƽ�ϵͳ��Ҫ�ص��ע�Ŀ��⡣ 02 ��ȷʹ�ø��Ի��Ƽ� ��ô������Ӧ����ô�Դ����Ի��Ƽ�ϵͳ�أ��ڱ��߿���������������Ϣ��ըʱ����������˵�����Ի��Ƽ��Ǹ��ز����ٵĹ��ߡ�����һ������������Ի��Ƽ�ϵͳӰ���ʱ������������������ԭ�������Ҫ����IJ��Ǽ����������������ռ�����ƽ̨�� ����������˵�����Ի��Ƽ��㷨���������ַ�������˽����ƽ̨Ϊ���������п���ͨ�������ֶζ����ǵ���˽���ݽ�����ȡ�ͷ��������ԣ�����Ӧ�ò��ϵ�ȥ�˽���Ի��Ƽ������л��ƣ��������в������ĵط���˵���������������Ա��Ͻ��й������ϣ���Ա����Խ�������ճ������ϰ���Ƽ����Ǹ��Ի�����Ʒ�����������ʱ�����Dz���ϣ���������Ա��������Ϣ�����õ�����ϵ������ƽ̨�С� ���“��Ϣ�뷿”�����ɣ˹̹Ҳ�ڡ���Ϣ���а��ָ����“�µĴ�����������ʹ�����ø��ö����Ǹ���”�����ڸ��Ի��Ƽ���˵�����Dz�Ӧ��һζ��ȥ�Ŵ����������ڵIJ��㣬����Ӧ���ڲ��ϵ�ʹ����ȥ�˽⡢�ල�����������Ͼ�����ֻ�ǹ��ߣ����뻵ȡ��������ʹ�ù��ߵ��ˡ� ��ϵ������������AI֧�֣������п�ί���йش��ί�����ר���������
|
|||||||||||
 |
|||||||||||
 |
| �Ƽ����� |
| ͼƬ���� | ||||
|
|
||||
| �������� |
| �������� |
| ������� |

|

|