当前机器人系统在应对陌生任务与环境时,常因依赖有限数据和固定动作定义而表现欠佳,多场景通用泛化能力成为关键瓶颈。针对这一问题,智元机器人与香港大学共同研发了UniVLA——一种能够在不同机器人本体、场景与任务间实现泛化的通用策略学习系统。该系统构建了以任务为中心的隐式动作空间,融合语言指令与视频数据,完成从视觉理解、语义解析到动作执行的通用控制闭环。
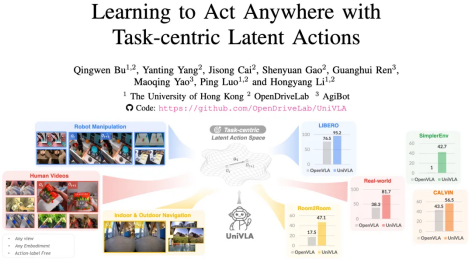
现有如RT-2、OpenVLA等模型虽具有一定通用性,却仍面临诸多瓶颈:训练数据多来源于人工采集的真机示范,未能充分引入多样化的视频资源;在不同机器人平台间迁移时,常需重新构建动作空间;此外,自回归推理方式导致响应速度较慢,且误差容易逐步累积。
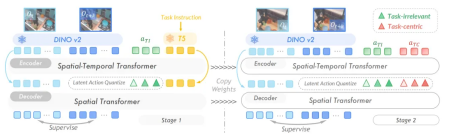
UniVLA采用了一种不同的技术路径。它不直接输出具体动作,而是先构建一个任务导向的隐式动作空间作为中间表征,再通过轻量解码将其转化为控制指令。该框架的运作分为三个阶段:首先,通过逆动力学建模与表征离散化,从多领域视频中学习紧凑的隐式动作表示;其次,基于大模型架构将视觉与语言信息映射为隐式动作序列,形成机器人无关的通用策略;最后,使用小型解码器实现隐式动作到真实控制信号的转换,支持跨平台高效部署。
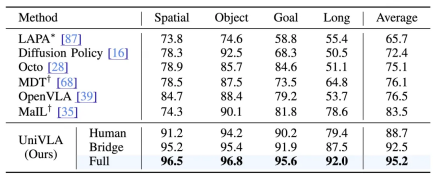
相较于OpenVLA,UniVLA在多项指标上展现出显著提升。其隐式动作空间不仅提高了对互联网视频数据的利用能力,还将推理速度提升至10Hz以上。在LIBERO与CALVIN等操控基准测试中,任务成功率平均提高18.5%。尤为突出的是,仅借助10%的训练数据,该系统在LIBERO-Goal任务中取得了62.4%的成功率,显著高于同等条件下的对比模型。
UniVLA还凭借仅12M参数的简单动作解码器,在“清理案板”等任务中实现超过80%的成功率,并维持较低推理延迟。

UniVLA通过隐式动作空间的设计,在保持高性能的同时降低对数据与算力的依赖,为机器人在多任务、多场景中的通用部署提供了新的实现路径。这一突破也体现出机器人学习的转变:从依赖精确动作重建,走向以语义理解为引导的隐式动作泛化。