 |
|

|
|
AI门槛再降低:中国移动推出模型服务平台MoMA, 首创Token集约化运营
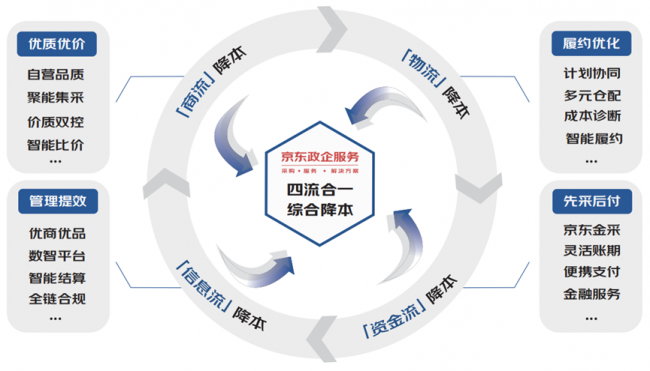
5月7-9日,2026移动云大会于苏州盛大开启。主论坛上,中国移动重磅发布了移动模型服务平台——MoMA。该平台接入超300款业界主流AI模型,模型丰富度行业领先,并首创Token集约化运营模式,旨在推动AI像水和电一样“随时可得、随处可用”,让人工智能真正走进千家万户、服务千行百业。 当前,大模型参数规模持续攀升,但高昂的调用成本、碎片化的接入方式以及算力资源的不透明管理,仍制约着AI在千行百业的规模化渗透。在这样的情况下,MoMA的推出被业内视为降低AI应用成本、简化接入流程的一次重要尝试。
开放普惠,让AI触手可及 MoMA构建了“一次接入、智能优选、普惠可用、安全可信” 的一站式模型服务体系,着力降低AI应用门槛。 在接入层面,该平台提供统一API网关,用户一次接入即可调用平台全部模型资源。目前,MoMA已接入中国移动自研“九天”基座大模型,以及DeepSeek、通义千问、豆包、Kimi、GLM等业界优质模型,覆盖文本生成、语音处理、多模态理解等多项能力,满足政务、金融、工业、医疗、教育等多场景应用需求。 在调度方面,MoMA首创智能路由引擎,自动分析用户需求,灵活切换“成本优先”“效果优先”“均衡优先”等三种策略,为用户动态匹配最适合的模型。当模型出现超时、限流或故障时,平台可自动实现秒级切换,确保业务连续不中断。 在成本控制上,MoMA平台基于国产算力部署自研推理引擎,结合智能路由对长尾模型资源调度,实现单位Token成本压降约30%,资源占用率降低50%以上。此外,智能缓存、上下文复用、Token压缩等相关技术手段运用进一步降低了使用成本。平台遵循中立路由原则,帮助用户在业务效果与算力成本之间找到最优平衡。 在服务保障方面,MoMA推出“机密模型”服务,将模型部署在机密容器中,基于硬件隔离技术保障计算过程的数据安全,做到“可用不可见”。这一能力覆盖从芯片到应用的全链路机密计算,为政务、金融等数据安全要求较高的场景提供了可靠支撑。
集约运营,助力Token高效调用 开放普惠主要解决“用得起、用得上”的问题,集约化运营则聚焦“用得好、管得住”难点。 据介绍,MoMA围绕Token全生命周期,构建了从精准计量、风险管控到经营分析的完整运营闭环体系,实现算力资源的清晰记录、高效流转与安全管控,推动算力资源规范、集约化利用。 实时精准计量,用多少、算多少。平台实施流式实时计费,用户使用Token计费端到端时延不超过1分钟,实现“即用即付”,有效破解传统按包计费模式的资源浪费以及账单消费缺乏透明度的问题。 运用专属风控,可追溯、可闭环。MoMA搭建了专属风控机制,保证Token计费全流程可追溯、可审计、可闭环,从根源上杜绝资源挤占、费用超支以及服务中断的风险,确保每一笔 Token消耗清晰透明。 提供链路观测,有支撑、有依据。平台提供全链路可观测能力,实时采集时延、吞吐量、Token消耗、GPU资源等关键指标,将监控、预警、诊断整合为一体化运营指标体系,覆盖客户、订购、使用、收入等多维度数据。AI投入与产出一目了然,为用户经营决策提供了具体依据。 中国移动此次推出MoMA平台,既是运营商依托网络与算力基础设施优势向AI服务领域延伸的缩影,也反映了行业对“模型即服务”(MaaS)集约化、普惠化方向的共识。
下一步,中国移动将不断提升移动模型服务平台MoMA服务质效,携手产业伙伴,共同释放算力新动能、拓展智能新空间,推动人工智能更加广泛、高效、安全地服务经济社会发展。
|
|||||||||||
 |
|||||||||||
 |
| 推荐文章 |
| 图片主题 | ||||
|
|
||||
| 热门文章 |
| 最新文章 |
| 相关文章 |

|

|